ZooKeeper 分布式協(xié)調(diào)服務(wù)的核心原理及其對(duì)數(shù)據(jù)處理與存儲(chǔ)的支持
在當(dāng)今大規(guī)模分布式系統(tǒng)架構(gòu)中,服務(wù)的協(xié)調(diào)與狀態(tài)管理是確保系統(tǒng)高可用、高一致性的基石。Apache ZooKeeper作為一個(gè)開源的分布式協(xié)調(diào)服務(wù),通過其簡(jiǎn)潔而強(qiáng)大的數(shù)據(jù)模型與協(xié)議,為上層應(yīng)用提供了可靠的分布式鎖、配置管理、命名服務(wù)、集群管理等核心功能,并成為眾多大數(shù)據(jù)處理與存儲(chǔ)框架(如Apache Hadoop, Kafka, HBase)不可或缺的依賴。
一、 ZooKeeper核心原理
ZooKeeper的設(shè)計(jì)哲學(xué)是提供一個(gè)簡(jiǎn)單、高性能、高可用的協(xié)調(diào)內(nèi)核。其核心原理圍繞以下幾個(gè)關(guān)鍵概念展開:
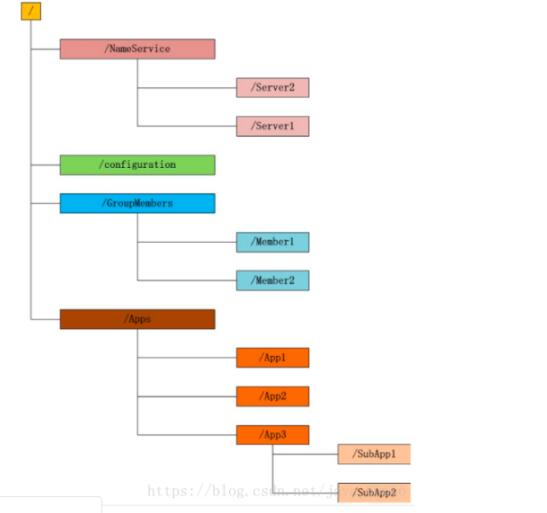
- 數(shù)據(jù)模型(ZNode樹):ZooKeeper維護(hù)一個(gè)類似文件系統(tǒng)路徑的層次化命名空間(稱為ZNode樹)。每個(gè)ZNode節(jié)點(diǎn)可以存儲(chǔ)少量數(shù)據(jù)(默認(rèn)上限1MB),并可以擁有子節(jié)點(diǎn)。ZNode分為持久節(jié)點(diǎn)和臨時(shí)節(jié)點(diǎn),后者在客戶端會(huì)話結(jié)束時(shí)自動(dòng)刪除,這一特性是實(shí)現(xiàn)服務(wù)發(fā)現(xiàn)和集群成員管理的基礎(chǔ)。
- 會(huì)話(Session)與 Watcher機(jī)制:客戶端與ZooKeeper集群建立連接后,會(huì)創(chuàng)建一個(gè)會(huì)話。會(huì)話具有超時(shí)時(shí)間,通過心跳機(jī)制保持活性。Watcher是客戶端在特定ZNode上設(shè)置的一次性監(jiān)聽器,當(dāng)該節(jié)點(diǎn)狀態(tài)(數(shù)據(jù)變更、子節(jié)點(diǎn)列表變更等)發(fā)生變化時(shí),ZooKeeper服務(wù)器會(huì)向客戶端發(fā)送一個(gè)事件通知,這是實(shí)現(xiàn)分布式事件驅(qū)動(dòng)編程模型的關(guān)鍵。
- 原子廣播協(xié)議(Zab):這是ZooKeeper實(shí)現(xiàn)強(qiáng)一致性的核心。Zab協(xié)議保證了所有事務(wù)請(qǐng)求的順序性和原子性。其工作流程主要包括兩個(gè)階段:
- 領(lǐng)導(dǎo)者選舉:集群?jiǎn)?dòng)或領(lǐng)導(dǎo)者宕機(jī)時(shí),通過Fast Leader Election算法快速選舉出一個(gè)新的領(lǐng)導(dǎo)者(Leader)。
- 原子廣播(兩階段提交):所有寫請(qǐng)求由領(lǐng)導(dǎo)者處理。領(lǐng)導(dǎo)者將寫請(qǐng)求轉(zhuǎn)化為一個(gè)事務(wù)提案(Proposal) 廣播給所有跟隨者(Follower)。當(dāng)收到超過半數(shù)的確認(rèn)后,領(lǐng)導(dǎo)者會(huì)發(fā)送提交(Commit) 指令,所有服務(wù)器(包括領(lǐng)導(dǎo)者自身)才會(huì)真正執(zhí)行該事務(wù)并更新內(nèi)存數(shù)據(jù)。這確保了集群中多數(shù)派服務(wù)器數(shù)據(jù)狀態(tài)的一致,即“過半寫成功”原則。
- 集群角色與讀寫流程:
- 領(lǐng)導(dǎo)者(Leader):負(fù)責(zé)處理所有寫請(qǐng)求和事務(wù)性操作,發(fā)起提案與提交。
- 跟隨者(Follower):參與領(lǐng)導(dǎo)者選舉,處理客戶端讀請(qǐng)求(直接返回本地?cái)?shù)據(jù),實(shí)現(xiàn)高吞吐讀),并參與事務(wù)提案的投票。
- 觀察者(Observer):與Follower類似,處理讀請(qǐng)求,但不參與投票。用于在不影響寫性能的前提下橫向擴(kuò)展讀能力。
二、 ZooKeeper如何支持?jǐn)?shù)據(jù)處理與存儲(chǔ)服務(wù)
憑借其強(qiáng)大的協(xié)調(diào)能力,ZooKeeper成為了眾多大數(shù)據(jù)組件中“元數(shù)據(jù)管理”和“集群協(xié)調(diào)”的“總控中心”。
- 配置管理(Configuration Management):
- 場(chǎng)景:在Hadoop、Kafka等分布式集群中,有大量動(dòng)態(tài)配置(如Broker列表、分區(qū)Leader信息、任務(wù)調(diào)度參數(shù))需要被所有節(jié)點(diǎn)一致地訪問和更新。
- 實(shí)現(xiàn):這些配置信息被存儲(chǔ)在ZooKeeper的持久ZNode中。各工作節(jié)點(diǎn)啟動(dòng)時(shí)或通過Watcher監(jiān)聽這些節(jié)點(diǎn)。當(dāng)配置變更時(shí),管理者更新ZNode數(shù)據(jù),所有監(jiān)聽該節(jié)點(diǎn)的客戶端會(huì)立刻收到通知并拉取最新配置,實(shí)現(xiàn)配置的集中化、動(dòng)態(tài)化管理。
- 命名服務(wù)與元數(shù)據(jù)存儲(chǔ)(Naming Service & Metadata Store):
- 場(chǎng)景:HBase需要知道RegionServer的地址和Region的分布;Kafka需要維護(hù)Broker、Topic、Partition的元數(shù)據(jù)及Partition與Leader的映射關(guān)系。
- 實(shí)現(xiàn):這些服務(wù)的元數(shù)據(jù)被精心組織在ZooKeeper的ZNode樹上。例如,HBase在ZooKeeper中維護(hù)
/hbase/master(主服務(wù)器地址)、/hbase/rs(RegionServer列表)等節(jié)點(diǎn)。客戶端通過查詢ZooKeeper來定位服務(wù),服務(wù)實(shí)例通過創(chuàng)建臨時(shí)節(jié)點(diǎn)來注冊(cè)自己。
- 分布式鎖與領(lǐng)導(dǎo)者選舉(Distributed Lock & Leader Election):
- 場(chǎng)景:HDFS中NameNode的高可用(HA)方案、YARN ResourceManager的HA、以及任何需要避免“腦裂”的分布式主從架構(gòu)。
- 實(shí)現(xiàn):利用ZooKeeper的臨時(shí)順序節(jié)點(diǎn)(EPHEMERAL_SEQUENTIAL) 特性可以輕松實(shí)現(xiàn)分布式鎖和領(lǐng)導(dǎo)者選舉。競(jìng)爭(zhēng)者都在一個(gè)指定的父節(jié)點(diǎn)下創(chuàng)建臨時(shí)順序子節(jié)點(diǎn),編號(hào)最小的節(jié)點(diǎn)獲得鎖或成為領(lǐng)導(dǎo)者。通過Watcher監(jiān)聽前一個(gè)序號(hào)節(jié)點(diǎn)的消失,可以實(shí)現(xiàn)公平鎖和自動(dòng)的領(lǐng)導(dǎo)者切換。
- 集群成員管理與健康監(jiān)測(cè)(Cluster Membership & Health Monitoring):
- 場(chǎng)景:實(shí)時(shí)感知Kafka Broker、HBase RegionServer等服務(wù)的上線與下線。
- 實(shí)現(xiàn):服務(wù)實(shí)例在啟動(dòng)時(shí),在ZooKeeper的特定路徑下(如
/brokers/ids)創(chuàng)建一個(gè)臨時(shí)子節(jié)點(diǎn)來注冊(cè)自己。由于臨時(shí)節(jié)點(diǎn)與會(huì)話綁定,一旦服務(wù)進(jìn)程崩潰或網(wǎng)絡(luò)斷開,其會(huì)話超時(shí)后,該臨時(shí)節(jié)點(diǎn)會(huì)被自動(dòng)刪除。其他服務(wù)或監(jiān)控中心通過監(jiān)聽該父節(jié)點(diǎn)的子節(jié)點(diǎn)變化,即可實(shí)時(shí)感知集群拓?fù)涞淖兓?/li>
三、 優(yōu)勢(shì)與挑戰(zhàn)
優(yōu)勢(shì):ZooKeeper通過Zab協(xié)議提供了順序一致性保證,即所有更新按全局順序生效,客戶端看到的更新順序一致。其提供的原語(如臨時(shí)節(jié)點(diǎn)、順序節(jié)點(diǎn)、Watcher)雖然簡(jiǎn)單,但足以構(gòu)建復(fù)雜的分布式協(xié)作場(chǎng)景。
挑戰(zhàn):ZooKeeper本身是CP系統(tǒng)(優(yōu)先保證一致性和分區(qū)容錯(cuò)性),在網(wǎng)絡(luò)分區(qū)發(fā)生時(shí)可能犧牲可用性。Watcher是一次性的,客戶端需要小心處理以避免丟失事件。對(duì)于超大規(guī)模(如數(shù)萬節(jié)點(diǎn))的頻繁配置變更場(chǎng)景,其性能和可擴(kuò)展性可能面臨壓力,此時(shí)可考慮如etcd、Consul等替代方案,或進(jìn)行合理的架構(gòu)分層。
###
ZooKeeper作為分布式系統(tǒng)的“潤(rùn)滑劑”和“基石”,其精妙的設(shè)計(jì)將復(fù)雜的分布式一致性問題封裝起來,為上層的分布式數(shù)據(jù)處理與存儲(chǔ)系統(tǒng)提供了一個(gè)可靠、高效的協(xié)調(diào)平臺(tái)。理解其原理,對(duì)于設(shè)計(jì)、開發(fā)和運(yùn)維依賴它的各類大數(shù)據(jù)系統(tǒng)至關(guān)重要。盡管新工具不斷涌現(xiàn),但ZooKeeper在要求強(qiáng)一致性的核心協(xié)調(diào)領(lǐng)域,依然占據(jù)著不可替代的地位。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.hgslw.cn/product/54.html
更新時(shí)間:2026-06-19 01:49:46